An OpenEnv environment where LLM agents learn to migrate code across breaking API contract changes. We trained a Manager on real Stripe, GitHub, Twilio, Slack, and OpenAI version diffs and watched it improve through GRPO.
Can a 7B model learn to migrate 415 real API breaking changes? Run the demo below to see what we trained, or skip to The Story to see the journey from cold start to first light.
Standard OpenEnv contract: reset, step, state over HTTP, plus a stateful WebSocket session at /ws for multi step episodes. Browse the full OpenEnv API contract.
API vendors ship breaking changes every quarter. There is no shared training ground for an LLM to learn the recurring skill of safe migration.
The Impact
One to three weeks of senior engineer time per migration. Same teams hit the same class of problem 18 months later, because nobody captured the lessons.
Our Solution
An OpenEnv environment with multi agent dispatch, persistent memory, adaptive curriculum, and a five component anti hacking reward. The trained Manager you see in the demo is proof the environment works.
...
Demo Scenarios
5
API Providers
Qwen2.5-7B
Base Model + LoRA
GRPO
RL Method
Try a live episode
Pick a scenario, hit run, and watch the Manager call its specialists in real time. Each step shows the per component reward breakdown.
Pick a scenario
v1 spec, abridged
select a task to see v1
v2 spec, abridged
select a task to see v2
Live episode
No episode running. Pick a scenario above and hit run.
Reward breakdown, per component
Breaking change detection (33%)0.00
Migration patch correctness (28%)0.00
Backward compat preservation (24%)0.00
Rollback plan completeness (10%)0.00
Simplicity bonus (5%)0.00
Final score: --
Episode transcript with findings
No episode run yet
Run the optimal plan above to see a step by step transcript with what each specialist did.
Key findings (this session)
Episodes run: 0
Success rate: --
Average score: --
Average steps to fix: --
Human Agent mode
Take the Manager's seat. Reset the env to a scenario, type one action at a time as JSON, click Step, and watch the observation update on the right. This is the same OpenEnv contract that programmatic agents call.
No observation yet. Click Reset Environment to start.
Action History
No actions taken yet
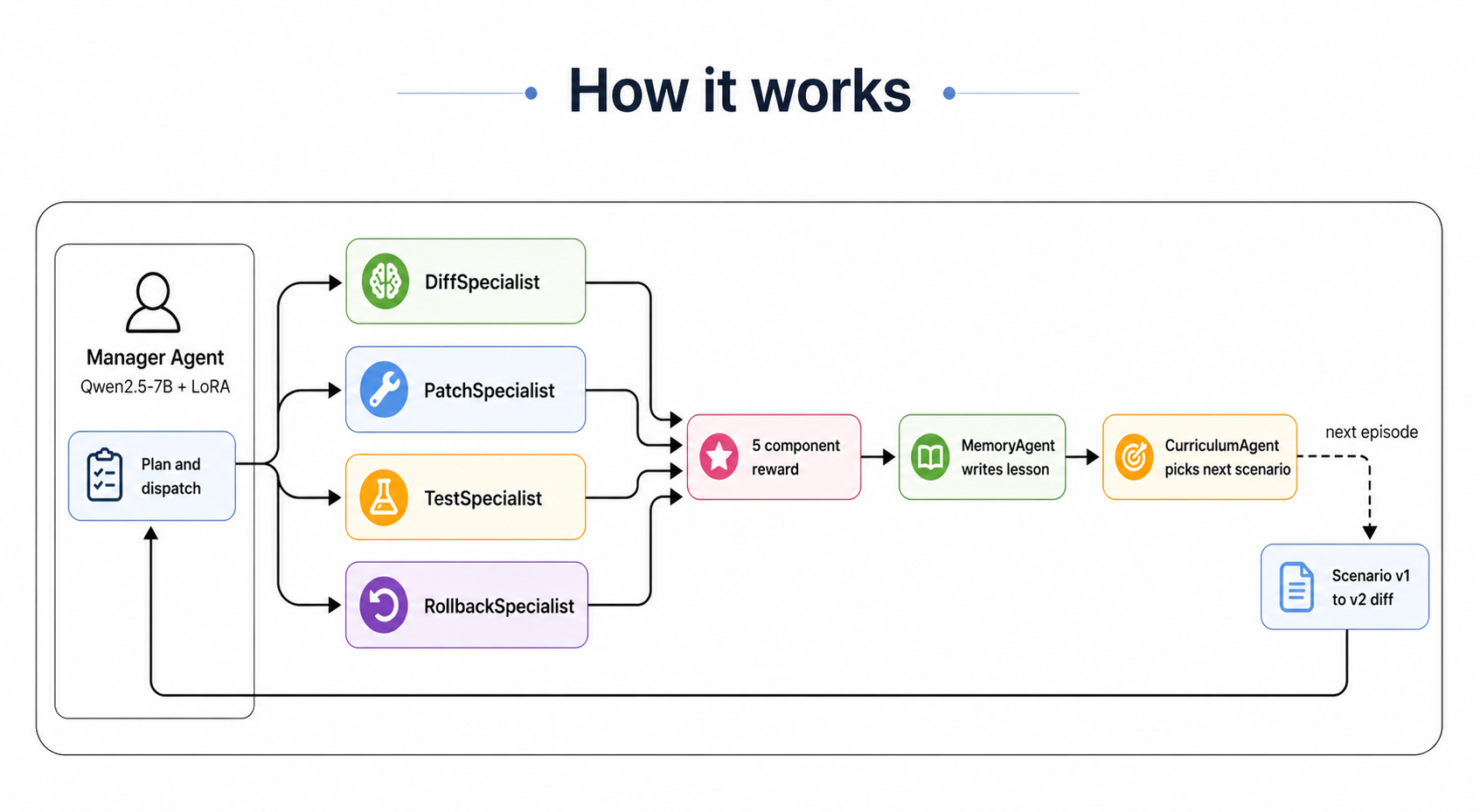
How it works
The Manager agent receives one scenario per episode. It calls four specialist agents in sequence, gets scored on five
independent reward components, and writes a markdown lesson at the end so the next episode starts smarter.
The Manager dispatches to DiffSpecialist, PatchSpecialist, TestSpecialist and RollbackSpecialist. Their outputs are scored by five independent reward components. The MemoryAgent writes a structured lesson, the CurriculumAgent picks the next scenario, and the loop continues.
Every action above flows through the OpenEnv contract. The web demo above is just a thin wrapper around the same /run_demo endpoint that judges and external clients call programmatically.
Reward design, made hard to game
Five independent verifiers. The Manager cannot read its own reward. Skipping rollback triggers a hard penalty.
Repeated dispatches do not stack. Memory is write protected from the Manager. Anti hacking story is documented in detail in
REWARD_DESIGN.md.
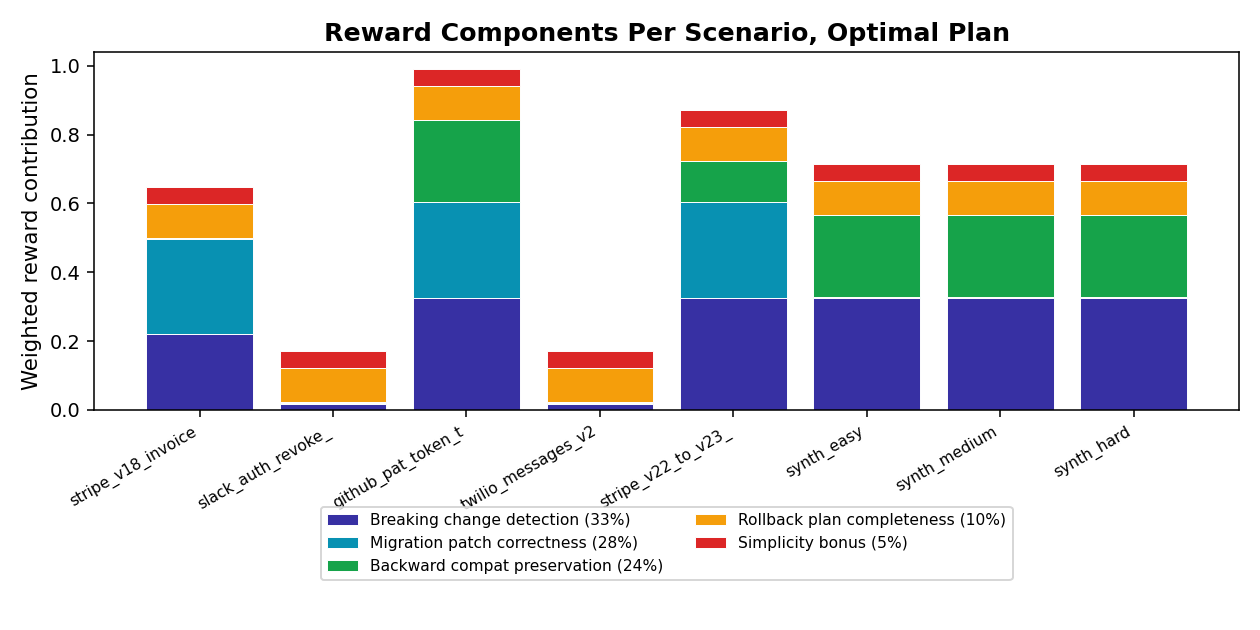
total_reward =
0.33 * breaking_change_detection_score # F1 over labeled breaking changes
+ 0.28 * migration_patch_correctness # template match per change_type
+ 0.24 * backward_compat_preservation # TestSpecialist pass rate
+ 0.10 * rollback_plan_completeness # rollback verifier
+ 0.05 * simplicity_bonus # fewer steps wins
- 0.10 if dispatch_rollback was never called
clamped to (0.01, 0.99)
The Story, how the environment and the agent improved together
We trained two runs. The journey from the first to the second is the most useful thing about this submission. The environment is what came out of it.
Act 1, the cold start
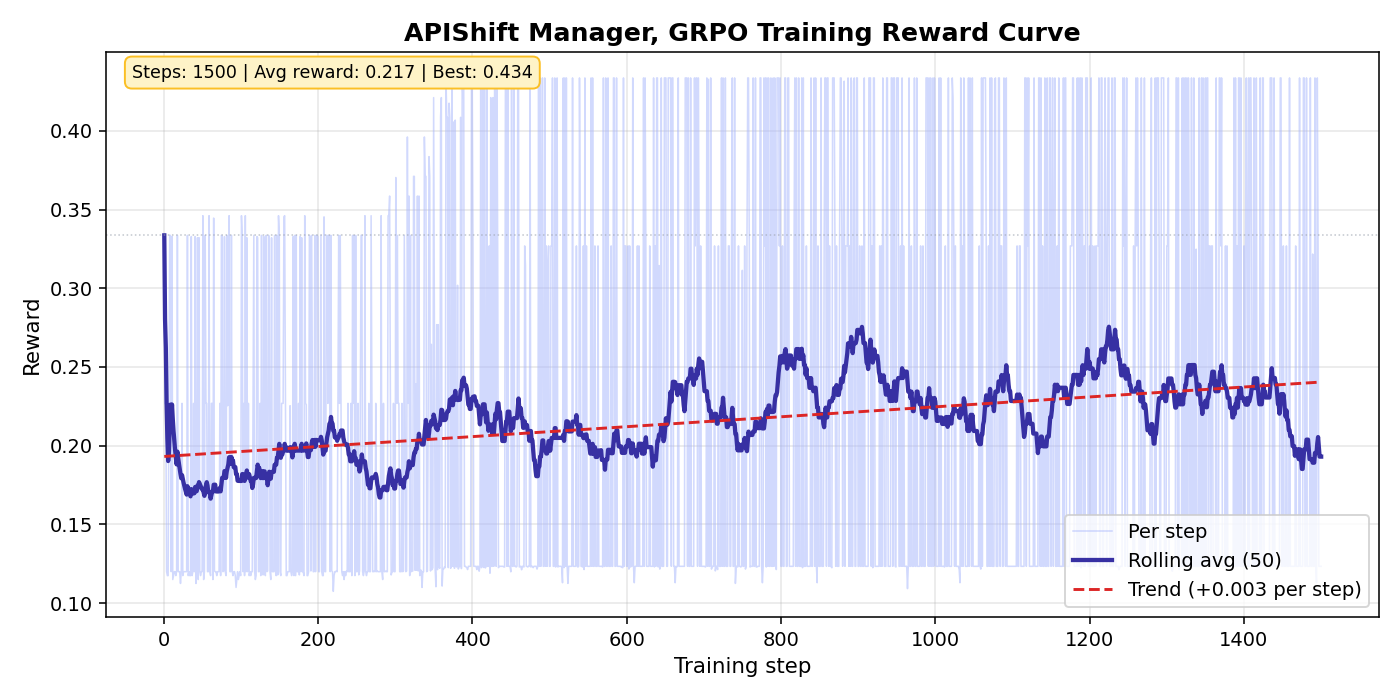
First GRPO run with the obvious config. num_generations=4, temperature 1.0, single tier reward. Within ten steps the reward locked at 0.01. Model output prose instead of JSON. Reward variance was zero. Gradient norm was zero. The model was not learning.
Act 2, the diagnosis
Reward had no gradation between "no JSON at all" and "some JSON but wrong format". All four completions in a batch landed at the same minimum. GRPO needs variance within the batch to compute advantages. We had none.
Act 3, the reward fights back
Three changes. Added a partial credit layer (0.02 per valid JSON command, 0.02 for ending with submit). Bumped num_generations from 4 to 8. Bumped temperature 1.0 to 1.2. Dry run reward standard deviation jumped from 0.0 to 0.12.
Act 4, first light
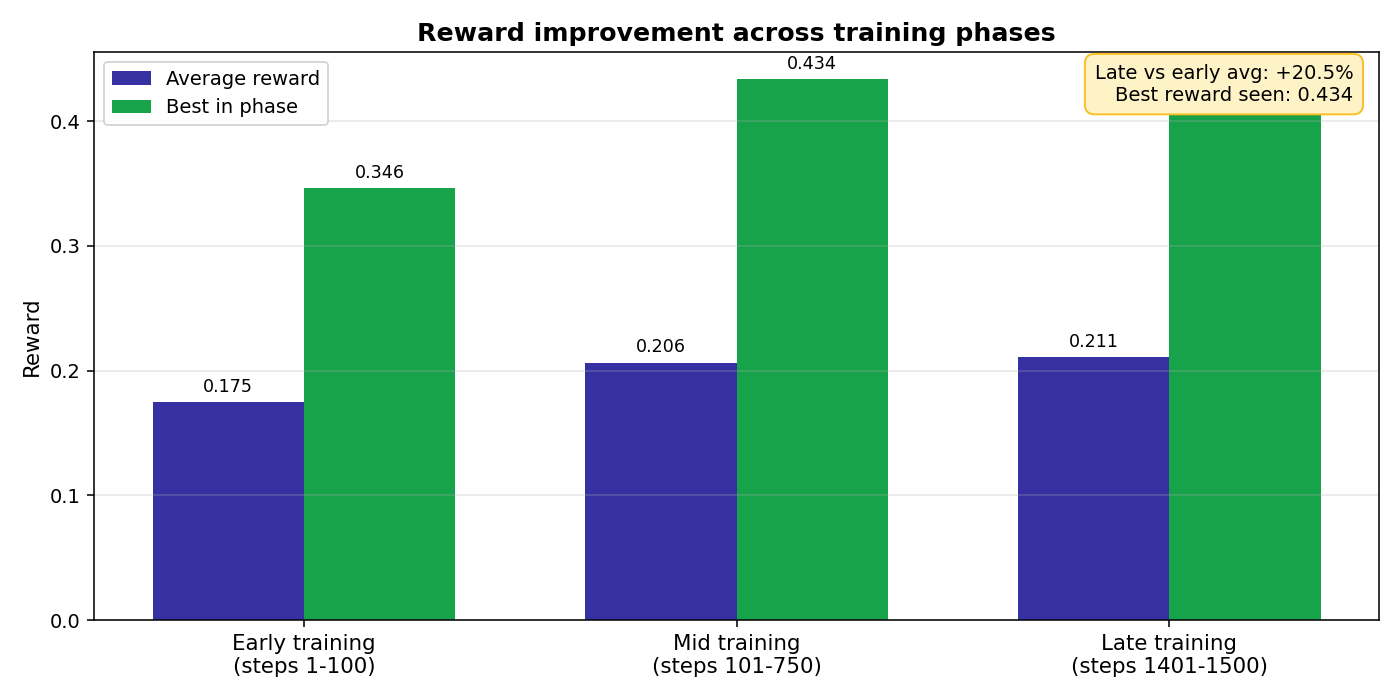
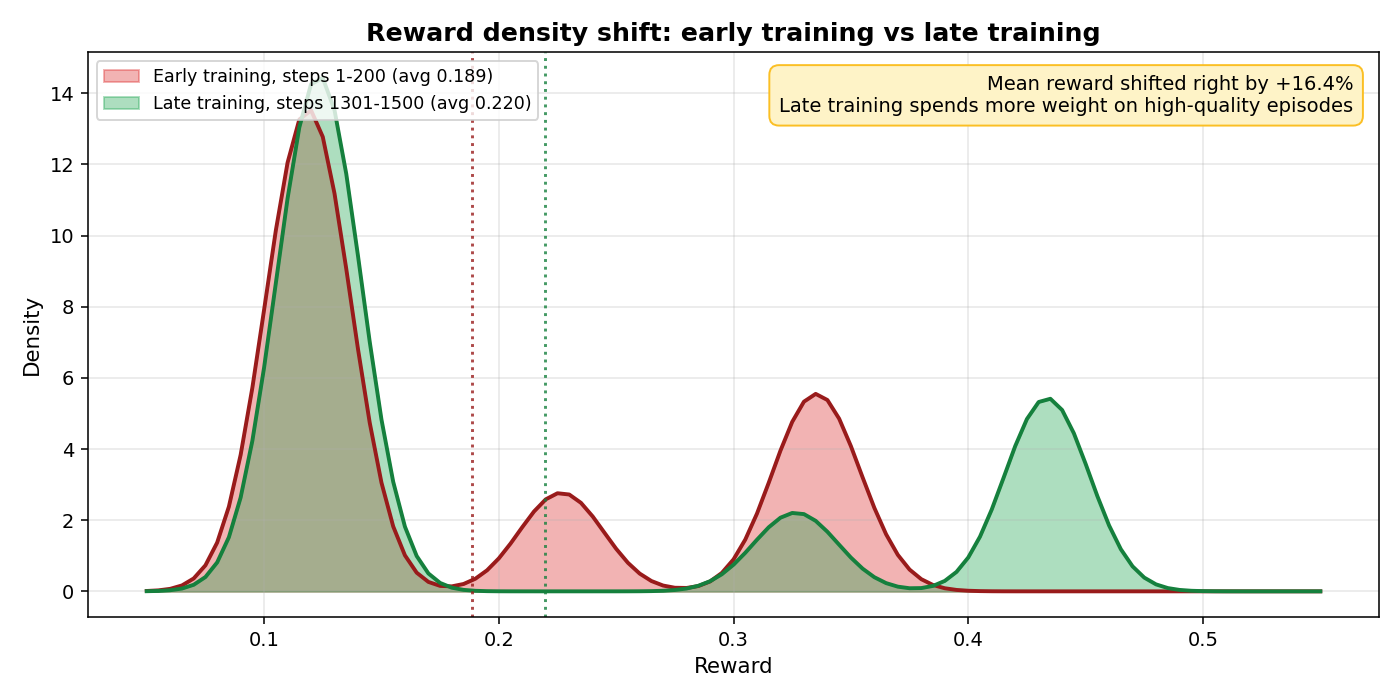
By step 100, reward average 0.175. By step 200, 0.20. Peak phase around step 900, averaging 0.245 with a single batch peak of 0.434. Forty four percent of the steps in the early phase fired real gradient updates. The Manager had learned the JSON workflow.
What the Manager learned
Output JSON action blobs, never prose
Always call dispatch_diff before any patch
Patch each detected breaking change by its real change_id, not a placeholder
Always call dispatch_rollback before submit (the hard penalty taught it this)
End with submit, never leave the episode hanging
What we learned, from the Manager's failures
Cold start GRPO needs partial credit, otherwise gradient is zero forever
num_generations=4 is the floor for structured output, eight is safer
Temperature 1.0 collapses output diversity, 1.2 keeps it
Per component reward decomposition belongs in the trainer state, not just the summary
Environment must reward intermediate format compliance, not just final correctness
The training infrastructure co-evolved with the agent. The reward function we ship today is the one the agent's failures forced us to design.
Breaking change types the environment can inject
The mutator in scenarios/layer2_synthetic/mutator.py can apply any of these to a real spec from scenarios/layer1_real/, producing infinite novel scenarios for training.
Change type
Real example
What the agent must produce
field_renamed
Stripe customer_email to customer_contact_email
Replace field references in request body and response handler
endpoint_removed
/v1/old_endpoint deleted in v2
Update URL and migrate request shape to the replacement endpoint
parameter_added_required
New required idempotency_key
Add the parameter at every call site
parameter_removed
Removed legacy_format
Drop the parameter from every call site
type_changed
amount int to string
Wrap calls in str / int conversion at boundary
auth_scheme_changed
GitHub PAT to Bearer
Swap the Authorization header construction
response_field_renamed
Twilio from to from_phone
Update response field accessors
enum_value_removed
Slack presence=auto removed
Map old values to new ones in client wrapper
multi_change
Two or three of the above in one episode
Diff first, classify all, patch each by id
Training results
Trained on a single A40 GPU with TRL GRPO and LoRA on Qwen2.5-7B. Plots below summarize the run.